GROUP BY와 HAVING
✒️ 2025-05-28 17:38 내용 수정
GROUP BY
- 특정 테이블에서 작은 그룹을 만들어 그에 해당하는 결과를 얻으려 할 때 사용한다.
- 개별 행의 결과뿐 아니라 특정 행 그룹에 대한 특성을 얻을 수 있다.
- 참고 자료 : IBM GROUP BY절, MS GROUP BY 절
SELECT 찾을내용
FROM 테이블명
WHERE 조건문
GROUP BY 특정그룹
ORDER BY 정렬기준;
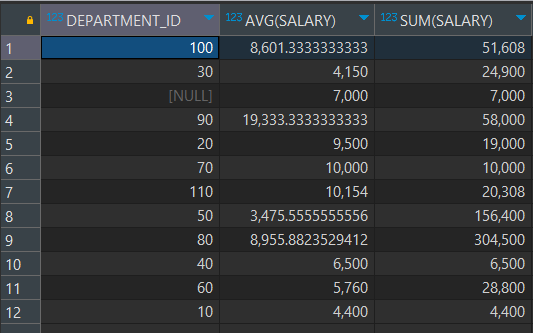
-- EMPLOYEES 테이블에서 각 부서별 급여의 평균과 총 합을 출력
SELECT DEPARTMENT_ID, AVG(SALARY), SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
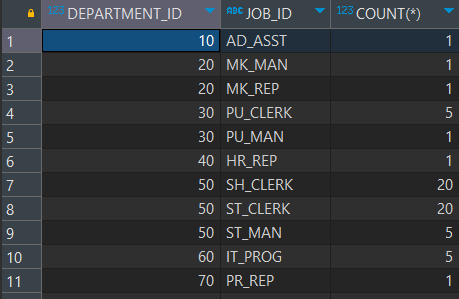
-- EMPLOYEES 테이블에서 부서별, 직종별로 그룹을 나눠서 인원수를 출력하되,
-- 부서 번호가 낮은 순으로 정렬
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID, JOB_ID
ORDER BY DEPARTMENT_ID;
GROUP BY 절 확장 구문
HAVING
- 일반적으로 COUNT와 집계 함수는 같이 조회할 수 없기 때문에 대신 HAVING을 사용해서 원하는 조건을 부여하여 데이터를 얻을 수 있다.
- 따라서 GROUP BY와 항상 함께 사용한다.
- 참고 자료 : MS HAVING절
- AND나 OR를 사용하여 조건을 여러 개 추가할 수 있다.
- 데이터의 조건문이 집계 함수가 아니라면 WHERE에 작성하는 것이 구분에 용이하고 데이터 처리에도 도움이 된다.
- WHERE 절로 그룹화 과정에 불필요한 행을 미리 제외한 후 HAVING 절로 조건별 데이터를 처리하기 때문
- HAVING 절은 그룹을 나타내는 결과 집합의 행에만 적용되지만, WHERE 절은 개별 행에 적용된다.
SELECT 찾을내용
FROM 테이블명
WHERE 조건문
GROUP BY 특정그룹
HAVING 조건문
ORDER BY 정렬기준;
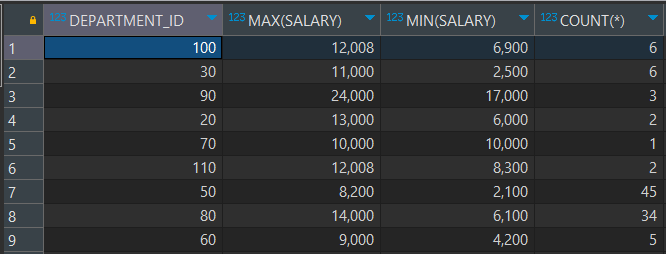
-- EMPLOYEES 테이블에서 각 부서의 급여의 최대값, 최소값, 인원수를 출력하되,
-- 급여의 최대값이 8000 이상인 결과만 조회
SELECT DEPARTMENT_ID, MAX(SALARY), MIN(SALARY), COUNT(*)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING MAX(SALARY) >= 8000;
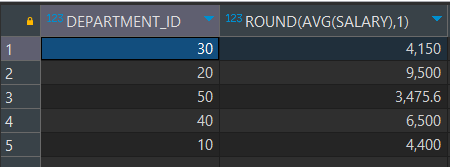
-- EMPLOYEES 테이블에서 각 부서별 평균 급여를 소수점 첫번째 자리 까지 출력(반올림)하되,
-- 평균 급여가 10000 미만이고, 부서 번호가 50번인 부서만 조회
SELECT DEPARTMENT_ID, ROUND(AVG(SALARY), 1)
FROM EMPLOYEES
WHERE DEPARTMENT_ID <= 50 -- 부서 번호 조건으로 먼저 그룹 데이터를 추린다.
GROUP BY DEPARTMENT_ID
HAVING ROUND(AVG(SALARY), 1) < 10000;
MySQL에서 사용 시 WITH ROLLUP, GROUPING()
- WITH ROLLUP : GRUOP BY 절과 함께 사용하며, 전체 그룹 합계(WITH ROLLUP, super-aggregate)와 작은 그룹별 합계(GROUP BY, aggregate, 서브그룹)를 모두 확인할 때 사용한다.
- 참고 자료 : MySQL GROUP BY Modifiers, Inpa dev's MySQL WITH ROLLUP & Grouping 함수
- 전체 그룹 합계의 필드는 NULL과 통계 형태로 표시된다.
- GROUP BY로 여러 컬럼이 들어있는 경우, 각각의 컬럼별로 생성된 서브 그룹 단위의 전체 통계도 함께 산출한다.
SELECT 컬럼명
FROM 테이블명
WHERE 조건절
GROUP BY 컬럼명 WITH ROLLUP;
- GROUPING() : GROUP BY에서 사용된 ROLLUP과 함께 사용하여, WITH ROLLUP으로 산출된 통계 결과인 NULL 필드값과 실제 데이터에 있는 NULL 값을 구별하지 못할 때 이를 구분하기 위해 사용한다.
- NULL로 표시된 해당 열이 subtotal을 표시한다면 1을, 그 외의 값이라면 0을 반환한다.
- 참고 자료 : MySQL Group by
- SELECT, HAVING 절, ORDER BY 절에서 사용할 수 있다.
- GROUPING() 대상은 반드시 GROUP BY 대상 컬럼과 동일한 컬럼이어야 한다.
SELECT 컬럼명1, GROUPING(컬럼명1), 컬럼명2
FROM 테이블명
WHERE 조건절
GROUP BY 컬럼명1 WITH ROLLUP;
Oracle에서 사용시 ROLLUP, CUBE, GROUPING()
참고 자료 : Oracle ROLLUP, Oracle ROLLUP extension
- ROLLUP : MySQL의 WITH ROLLUP과 마찬가지로 전체 그룹의 합계와 작은 그룹별 합계를 확인할 때 사용한다.
- 조합 가능한 작은 그룹에 대해서만 그룹별 합계를 만든다.
SELECT 컬럼명1, 컬럼명2
FROM 테이블명
WHERE 조건절
GROUP BY ROLLUP(컬럼명1, 컬럼명2);
- CUBE : ROLLUP과 다르게 조합 가능한 모든 작은 그룹에 대한 그룹별 합계와 전체 그룹의 합계를 만들 때 사용한다.
- ROLLUP에서 그룹 조합을 바꿔서 확인하려면 ROLLUP(컬럼명1, 컬럼명2)를 ROLLUP(컬럼명2, 컬럼명1) 방식으로 바꿔 작성해서 확인해야 하지만, CUBE를 사용하면 한 번에 모든 조합을 확인할 수 있다.
SELECT 컬럼명1, 컬럼명2
FROM 테이블명
WHERE 조건절
GROUP BY CUBE(컬럼명1, 컬럼명2);
- GROUPING() : GROUP BY에서 사용된 ROLLUP과 함께 사용하여, WITH ROLLUP으로 산출된 통계 결과인 NULL 필드값과 실제 데이터에 있는 NULL 값을 구별하지 못할 때 이를 구분하기 위해 사용한다.
- NULL로 표시된 해당 열이 subtotal을 표시한다면 1을, 그 외의 값이라면 0을 반환한다.
- 참고 자료 : Oracle Analyzing Data with ROLLUP, CUBE, AND TOP-N QUERIES
- GROUPING() 대상은 반드시 GROUP BY 대상 컬럼과 동일한 컬럼이어야 한다.
SELECT 컬럼명1, GROUPING(컬럼명1), 컬럼명2
FROM 테이블명
WHERE 조건절
GROUP BY ROLLUP(컬럼명1);