Oracle SQL 함수
✒️ 2025-05-28 16:36 내용 수정
참고 자료 : 겨울섬's SQL 함수, Oracle Date
SQL 내장 함수
SQL에서 기본적으로 제공하는 함수
- 공식 문서 : Oracle SQL Functions
- SQL의 DQL(SELECT문)에서 주로 사용한다. (DQL(Data Query Language)과 키워드#SELECT)
- 단일 행 함수 : 입력 값이 단일 행 1개의 값이며, 반환 값도 단일 행 1개이다.
- 집계 함수(복수 형 함수) : 입력 값이 여러 개의 행이며, 반환 값은 단일 행 1개이다.
문자 함수
| 함수 | 설명 |
|---|---|
| ASCII | 지정된 문자의 ASCII값 반환 |
| CHR | 지정된 숫자와 일치하는 ASCII 코드 반환 |
| RPAD | 왼쪽 정렬 후 오른쪽에 지정한 문자 삽입 |
| LPAD | 오른쪽 정렬 후 왼쪽에 지정한 문자 삽입 |
| TRIM | 문자열의 시작 이전 지점과 끝 이후 지점의 공백 제거 |
| RTRIM | 문자열 오른쪽(끝 이후) 공백 제거 |
| LTRIM | 문자열 왼쪽(시작 이전) 공백 제거 |
| LOWER | 지정된 문자를 모두 소문자로 변환 |
| UPPER | 지정된 문자를 모두 대문자로 변환 |
| INITCAP | 지정된 문자열의 첫 단어를 대문자, 나머지는 소문자로 변환 |
| INSTR | 특정 문자의 위치(INDEX)를 반환 |
| LENGTH | 문자열의 길이를 반환 |
| SUBSTR | 선택 위치(INDEX)부터 원하는 길이의 문자를 반환. 문자열 추출 |
| REPLACE | 문자열의 첫 번째 파라미터 문자를 두 번째 파라미터 문자로 변환 |
| CONCAT | 두 문자열을 연결한 결과를 반환 |
1. ASCII와 CHR
-- ASCII
SELECT ASCII('알파벳') FROM DUAL; -- DUAL : Oracle에서 제공하는 가상 테이블
-- CHR
SELECT CHR(숫자) FROM DUAL;
SELECT ASCII('A') FROM DUAL; -- DUAL : Oracle에서 제공하는 가상 테이블
SELECT CHR(97) FROM DUAL;
65
a
2. RPAD와 LPAD
- 문자열의 길이가 총 문자열 길이보다 작으면 빈 공간을 '삽입할문자'로 채운다.
- 문자열의 길이가 총 문자열 길이보다 크다면 총 문자열 길이까지만 표시된다.
-- RPAD
SELECT RPAD(문자열 , 총문자열길이, '삽입할문자') FROM DUAL;
SELECT RPAD(컬럼명 , 총문자열길이, '삽입할문자') FROM 테이블명;
-- LPAD
SELECT LPAD(문자열 , 총문자열길이, '삽입할문자') FROM DUAL;
SELECT LPAD(컬럼명 , 총문자열길이, '삽입할문자') FROM 테이블명;
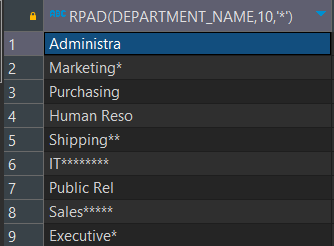
SELECT RPAD(' 안녕하세요' , 20, '*') FROM DUAL;
SELECT RPAD(DEPARTMENT_NAME , 10, '*') FROM DEPARTMENTS;
안녕하세요*****
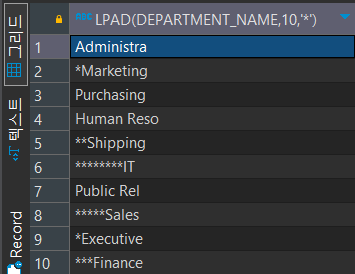
SELECT LPAD('안녕하세요 ' , 20, '*') FROM DUAL;
SELECT LPAD(DEPARTMENT_NAME , 10, '*') FROM DEPARTMENTS;
**안녕하세요 // 공백이 이 위치에서 끝난다.
3. TRIM, RTRIM, LTRIM
-- TRIM
SELECT TRIM('문자열') FROM DUAL;
SELECT TRIM('문자' FROM '원본문자열') FROM DUAL; -- 원본 문자열에서 문자를 공백으로 처리한다
-- RTRIM
SELECT RTRIM('문자열') FROM DUAL;
-- LTRIM
SELECT LTRIM('문자열') FROM DUAL;
SELECT TRIM(' HEL LO ') FROM DUAL;
SELECT TRIM('z' FROM 'zzzHELLOzzz') FROM DUAL;
HEL LO
HELLO
SELECT RTRIM(' HELLO ') FROM DUAL;
SELECT LTRIM(' HELLO ') FROM DUAL;
HELLO
HELLO // 공백이 이 위치에서 끝난다.
4. LOWER, UPPER, INITCAP
-- LOWER
SELECT LOWER('문자열') FROM DUAL;
-- UPPER
SELECT UPPER('문자열') FROM DUAL;
-- INITCAP
SELECT INITCAP ('문자열') FROM DUAL;
SELECT LOWER('ABCDEFG') FROM DUAL;
SELECT UPPER('abcdefg') FROM DUAL;
SELECT INITCAP ('Hello world!') FROM DUAL;
abcdefg
ABCDEFG
Hello World!
5. INSTR
- 참고 자료 : 젠트's 오라클 INSTR 함수 사용법 완벽 정리(CHARINDEX, IndexOf)
- 왼쪽에서 오른쪽 순서로 가장 먼저 검색된 문자의 위치만 반환한다.
- 문자가 문자열에 여러 개 포함되었을 때, 찾은 위치들을 지정하면 N번째로 찾은 문자의 위치를 얻을 수 있다.
- 검색을 시작할 위치를 지정하면 해당 위치부터 검색을 시작한다.
- 뒤에서부터 검색을 시작하려면 검색 시작 위치 파라미터를 음수로 준다.
- 문자가 문자열에 없다면 0을 반환한다.
SELECT INSTR('문자열', '검색할문자') FROM DUAL;
SELECT INSTR('문자열', '검색할문자', INDEX) FROM DUAL; -- 지정한 INDEX 부터 검색시작 (기본값 1)
SELECT INSTR('문자열', '검색할문자', -N) FROM DUAL; -- 뒤에서부터 N번째 문자부터 검색시작
-- 검색 시작 위치 START와 N번째 검색 문자 N을 주면 문자가 문자열에 여러 개 포함되었을 때
-- N번째로 찾은 문자의 위치를 반환한다.
SELECT INSTR('문자열', '검색할문자', START, N) FROM DUAL;
SELECT INSTR('Hello', 'l') FROM DUAL;
SELECT INSTR('Hello', 'l', 1, 2) FROM DUAL;
SELECT INSTR('HELLO', 'Z') FROM DUAL;
3 // 왼쪽에서 오른쪽 순서로 가장 먼저 검색된 문자의 위치만 반환
4 // l 중에서 두 번째로 찾은 l의 위치
0 // z는 문자열에 없다
6. LENGTH
SELECT LENGTH ('문자열') FROM DUAL;
SELECT LENGTH ('good evening') FROM DUAL;
12
7. SUBSTR, REPLACE, CONCAT
-- SUBSTR
SELECT SUBSTR('문자열', INDEX, LENGTH) FROM DUAL;
-- REPLACE
SELECT REPLACE ('문자열', '문자나문자열', '바꿀문자') FROM DUAL;
-- CONCAT
SELECT CONCAT ('문자열1 ', '문자열2') FROM DUAL;
SELECT SUBSTR('ABCDHELLOEFG', 5, 5) FROM DUAL;
SELECT REPLACE ('AAAAHELLOAAA', 'A', '*') FROM DUAL;
SELECT REPLACE ('ABCDHELLOABCD', 'ABCD', '*') FROM DUAL;
SELECT CONCAT ('Hello ', 'World!') FROM DUAL;
HELLO
****HELLO***
*HELLO*
Hello World!
숫자 함수
| 함수 | 설명 |
|---|---|
| ABS | 절댓값(absolute) 반환 |
| ROUND | 특정 자릿수를 반올림하여 반환 |
| FLOOR | 주어진 숫자보다 작거나 정수 중에서 주어진 숫자와 같은 값의 최대값을 반환 |
| CEIL | 주어진 숫자보다 크거나 정수 중에서 주어진 숫자와 같은 값의 최소값을 반환 |
| TRUNC | 특정 자릿수에서 잘라낸 결과를 반환 |
| SIGN | 주어진 값의 음수, 정수, 0 여부를 반환 |
| MOD | 나누기 후 나머지를 반환 |
| POWER | 주어진 숫자의 거듭 제곱을 반환 |
1. ABS
SELECT ABS(숫자) FROM DUAL;
SELECT ABS(-1.89) FROM DUAL;
1.89
2.ROUND
- 전달 받은 자릿수가 양수라면 소수점 아래 자리를, 음수라면 정수 부분에서 반올림을 한다.
- 기본값은 0이며, 0은 소수점 아래 첫 번째 자릿수이다.
SELECT ROUND(숫자, 자릿수) FROM DUAL;
SELECT ROUND(4.57, 1),
ROUND(251.07, -1),
ROUND(8721.5589)
FROM DUAL;
4.6 // 소수점 아래 두 번째 자릿수에서 반올림
250 // 일의 자리 숫자에서 반올림
8722 // 소수점 아래 첫 번째 자릿수에서 반올림
3. FLOOR, CEIL
-- FLOOR
SELECT FLOOR(숫자) FROM DUAL;
-- CEIL
SELECT CEIL(숫자) FROM DUAL;
SELECT FLOOR(4), FLOOR(4.5), FLOOR(-17.6) FROM DUAL;
SELECT CEIL(2), CEIL(2.5), CEIL(-43.2) FROM DUAL;
4, 4, -18 // FLOOR
2, 3, -43 // CEIL
4. TRUNC
- ROUND처럼 전달 받은 자릿수가 양수라면 소수점 아래 자릿수를, 음수라면 정수 부분 자릿수 이하를 잘라낸다.
- 기본값은 0이며, 0은 소수점 아래 첫 번째 자릿수이다.
- FLOOR와 비슷한 동작을 하는 것처럼 보이나, 음수에 특히 차이를 보인다.
- TRUNC는 전달 받은 자릿수 이하를 단순 제거(0으로 처리)하지만, FLOOR는 전달 받은 숫자보다 작은 정수들 중에서 최대값을 반환한다.
SELECT TRUNC(숫자, 자릿수) FROM DUAL;
SELECT TRUNC(542.27, 1),
TRUNC(78.10, -1),
TRUNC(473.057)
FROM DUAL;
SELECT TRUNC(-17.6) FROM DUAL;
542.2 // 소수점 아래 두 번째 자리수 이하를 모두 제거
70 // 일의 자리 숫자 이하를 모두 제거. 일의 자리는 0으로 처리
473 // 소수점 아래 첫 번째 자리수 이하를 모두 제거
-17 // FLOOR(-17.6) = -18 과는 다른 결과다.
5. SIGN
- 전달 받은 인자가 음수면 -1을, 0이면 0을, 양수면 1을, NULL이면 NULL을 반환
SELECT SIGN(숫자) FROM DUAL;
SELECT SIGN(-2),
SIGN(0),
SIGN(4),
SIGN(NULL)
FROM DUAL;
-1 // 음수는 -1을 반환
0 // 0은 0을 반환
1 // 양수는 1을 반환
NULL // NULL은 NULL을 반환
6. MOD
- Java와 JavaScript의 % 연산처럼 나누기 진행 후 나머지를 반환한다.
SELECT MOD(분모, 분자) FROM DUAL;
SELECT MOD(1, 3),
MOD(2, 3),
MOD(3, 3),
MOD(4, 3),
MOD(0, 3)
FROM DUAL;
1 // 1/3 = 몫 : 0, 나머지 : 1
2 // 2/3 = 몫 : 0, 나머지 : 2
0 // 3/3 = 몫 : 1, 나머지 : 0
1 // 4/3 = 몫 : 1, 나머지 : 1
0 // 0/3 = 몫 : 0, 나머지 : 0
7. POWER
SELECT POWER(숫자, 거듭제곱) FROM DUAL;
SELECT POWER(2, 1), POWER(2, 2), POWER(2, 3), POWER(2, 0)
FROM DUAL;
2, 4, 8, 1
날짜 함수
- SYSDATE : 현재 날짜와 시간을 표시
| 함수 | 설명 |
|---|---|
| ADD_MONTHS | 특정 날짜에 개월 수를 더함 |
| MONTHS_BETWEEN | 주어진 두 날짜 간격의 개월을 반환 |
| NEXT_DAY | 주어진 날짜 다음에 나타나는 지정 요일 날짜를 반환 |
| LAST_DAY | 주어진 일자가 포함된 월의 말일을 반환 |
| DATE(표현식) | 표현식에서 날짜 형식 데이터를 추출 |
날짜의 연산
- 날짜에서 TRUNC를 사용하면 당일 날짜로 계산하고, ROUND를 하면 정오를 기준으로 정오 이후엔 다음 날짜, 정오 이전엔 당일 날짜 반환한다.
- 날짜 +- 숫자 : 날짜에 일 수를 더하거나 뺀 날짜를 반환
SELECT SYSDATE + 3 FROM DUAL;
SELECT SYSDATE - 3 FROM DUAL;
2023-12-12 03:46:24.000 // 2023-12-09 에서 3일 후
2023-12-06 03:46:14.000 // 2023-12-09 에서 3일 전
- 날짜 - 날짜 : 두 날짜 사이의 일 수를 반환
- 날짜 + 날짜 는 허용되지 않는다.
SELECT SYSDATE - TO_DATE('2023-11-30', 'YYYY-MM-DD') FROM DUAL;
9.15461805555555 // 9일
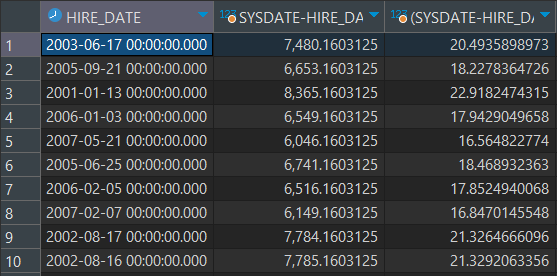
-- EMPLOYEES 테이블 사용
SELECT HIRE_DATE , SYSDATE - HIRE_DATE, (SYSDATE - HIRE_DATE)/365
FROM EMPLOYEES;
1. ADD_MONTHS
SELECT ADD_MONTHS(날짜, 개월수) FROM DUAL;
SELECT ADD_MONTHS(SYSDATE, 2) FROM DUAL;
SELECT ADD_MONTHS(SYSDATE, 12*2+1) FROM DUAL;
2024-02-09 03:22:56.000 // 2023-12-09 03:23:05.000 로부터 2개월 뒤
2026-01-09 03:28:30.000 // 2년 1개월 뒤
2. MONTHS_BETWEEN
- 날짜 1이 날짜 2보다 최근 날짜라면 양수를, 날짜 2가 날짜 1보다 최근 날짜라면 음수를 반환한다.
- 개월 수만 카운트하고 일수로는 계산하지 않는다.
SELECT MONTHS_BETWEEN(날짜1, 날짜2) FROM DUAL;
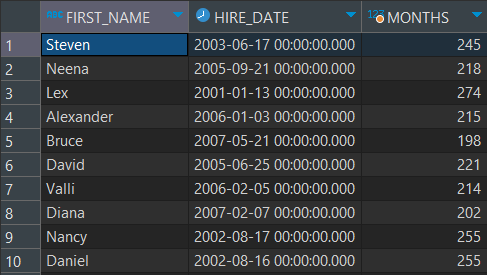
-- EMPLOYEES 테이블 사용
-- 모든 사원들이 입사일로부터 오늘까지 몇개월이 경과했는지 이름을 포함하여 출력
SELECT FIRST_NAME, HIRE_DATE , FLOOR(MONTHS_BETWEEN(SYSDATE, HIRE_DATE)) AS MONTHS
FROM EMPLOYEES;
-- EMPLOYEES 테이블 사용
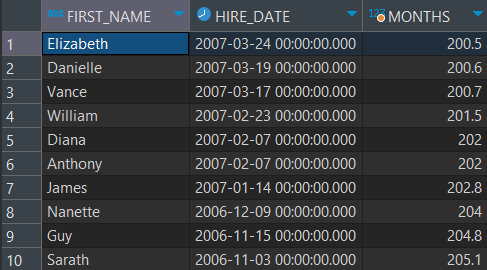
-- 사원들의 이름, 입사일, 입사 후 오늘까지의 개월 수를 조회하되,
-- 입사 기간이 200개월 이상인 사람만 출력하고
-- 입사 개월 수는 소수점 첫째 자리까지만 출력되도록 버림하고, 개월 수를 오름차순 정렬
SELECT FIRST_NAME, HIRE_DATE, TRUNC(MONTHS_BETWEEN(SYSDATE, HIRE_DATE), 1) AS MONTHS
FROM EMPLOYEES
WHERE TRUNC(MONTHS_BETWEEN(SYSDATE, HIRE_DATE), 1) >= 200
ORDER BY TRUNC(MONTHS_BETWEEN(SYSDATE, HIRE_DATE), 1);
3. NEXT_DAY
- 파라미터로 전달되는 숫자에 대응되는 요일
| 일요일 | 월요일 | 화요일 | 수요일 | 목요일 | 금요일 | 토요일 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
SELECT NEXT_DAY(날짜, 숫자) FROM DUAL;
SELECT NEXT_DAY(날짜, '요일') FROM DUAL; -- 요일 문자는 Oracle 언어 설정을 따라간다.
SELECT NEXT_DAY(SYSDATE, 1) FROM DUAL;
SELECT NEXT_DAY(SYSDATE-12, 5) FROM DUAL;
2023-12-10 03:38:06.000 // 12월 9일이 포함된 주의 일요일은 12월 10일
2023-11-30 03:39:31.000 // 12월 9일로부터 12일 전인 11월 27일이 포함된 주의 목요일은 11월 30일
4. LAST_DAY
SELECT LAST_DAY(날짜) FROM DUAL;
SELECT LAST_DAY(SYSDATE) FROM DUAL;
2023-12-31 03:54:13.000 // 2023-12-09 가 포함된 월의 월 말
명시적 형 변환 함수
| 함수 | 설명 |
|---|---|
| TO_CHAR | 날짜나 숫자를 형식에 맞춰 문자열로 변환 |
| TO_DATE | 문자열을 형식에 맞춰 날짜형으로 변환 |
| TO_NUMBER | 문자를 숫자로 변환 |
| 숫자만 있는 문자열은 묵시적으로 숫자 취급을 하므로 자주 사용하지 않는다. |
날짜 형식
| 형식 | 설명 |
|---|---|
| SCC, CC | 세기 |
| YYYY, YY | 연도 |
| MM | 월 |
| DD | 일 |
| DAY | 요일 |
| MON | 월 명(축약, JAN) |
| MONTH | 월 명(전체, JANUARY) |
| HH, HH24 | 시간 |
| MI | 분 |
| SS | 초 |
숫자 형식
| 형식 | 설명 | 표기 |
|---|---|---|
| 0 | 숫자, 앞부분 공백 시 0으로 채움 | '009' |
| B | 공백을 0으로 표시 | 'B99.9' |
| 9 | 숫자 | '9999' |
| , | 쉼표 표기 | '999,999' |
| . | 소수점 표기 | '99.9' |
| L | Local currency symbol(해당 지역 화폐 심볼) | 'L999' |
| $ | 숫자 앞 $ 표시 | '$999' |
| MI | 숫자의 오른쪽에 - 기호 추가 | '999MI' |
| EEEE | 지수 표기법 | '999EEEE' |
1. TO_CHAR
SELECT TO_CHAR(날짜, '날짜형식') FROM DUAL;
SELECT TO_CHAR(숫자, '숫자형식') FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD'),
TO_CHAR(SYSDATE, 'YYYY-MM-DD DAY'),
TO_CHAR(SYSDATE, 'YYYY-MM-DD HH:MI:SS')
FROM DUAL;
2023-12-09
2023-12-09 토요일
2023-12-09 03:58:41
SELECT TO_CHAR(574161, '9,999,999'),
TO_CHAR(16423, 'L9,999,999.99'),
TO_CHAR(54, '0999')
FROM DUAL;
574,161
₩16,423.00
0054
2. TO_DATE
SELECT TO_DATE('문자열', '날짜형식') FROM DUAL;
SELECT TO_DATE('2023.12.08'),
TO_DATE('12.08.2023', 'MM.DD.YYYY'),
TO_DATE('2023.12', 'YYYY.MM'),
TO_DATE('08', 'DD')
FROM DUAL;
2023-12-08 00:00:00.000
2023-12-08 00:00:00.000
2023-12-01 00:00:00.000 // 해당 월의 첫 날로 반환
2023-12-08 00:00:00.000 // SYSDATE 기준 현재 월의 해당 일로 반환
3. TO_NUMBER
SELECT TO_NUMBER('문자열') FROM DUAL;
SELECT TO_NUMBER('1234') FROM DUAL;
1234 // NUMBER 타입이다.
NULL 처리 함수
| 함수 | 설명 |
|---|---|
| NVL | NULL 대신 다른 값으로 변경 후 검색 |
| NVL2 | NULL일 때와 NULL이 아닐 때 값을 각각 설정 |
| NULLIF | 두 파라미터의 값을 비교해서 같으면 NULL을, 다르면 첫 번째 파라미터 값을 반환 |
1. NVL
SELECT NVL(값, 치환값) FROM DUAL;
SELECT NVL(컬럼명, 치환값) FROM DUAL;
SELECT NVL(NULL, 5) FROM DUAL;
5
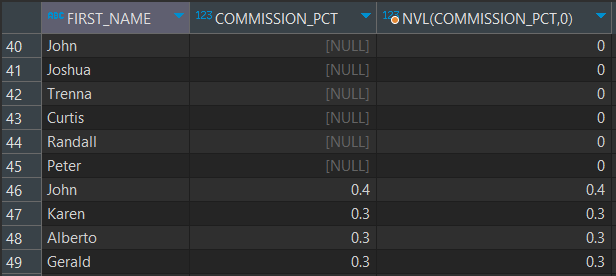
-- EMPLOYEES 테이블 사용
SELECT FIRST_NAME, COMMISSION_PCT, NVL(COMMISSION_PCT, 0) FROM EMPLOYEES;
2. NVL2
SELECT NVL2(값, NULL이아닐때치환값, NULL일때치환값) FROM DUAL;
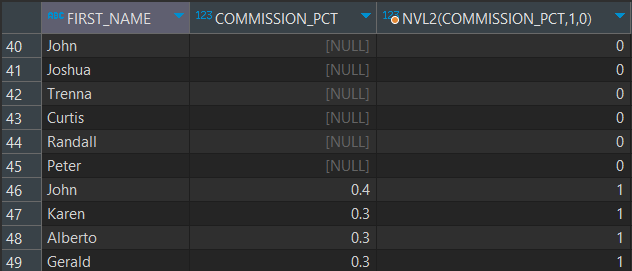
-- EMPLOYEES 테이블 사용
SELECT FIRST_NAME, COMMISSION_PCT, NVL2(COMMISSION_PCT, 1, 0) FROM EMPLOYEES;
3. NULLIF
SELECT NULLIF(비교값1, 비교값2) FROM DUAL;
SELECT NULLIF(3, 4) FROM DUAL;
SELECT NULLIF(2, 2) FROM DUAL;
3 // 두 값이 다르므로 첫 번째 파라미터 값을 반환
NULL // 두 값이 같으므로 NULL을 반환
순위 함수와 집계 함수
- 일반적으로 COUNT와 집계 함수는 같이 조회할 수 없다.
| 함수 | 설명 |
|---|---|
| RANK | 그룹 내 순위를 계산해서 NUMBER 타입으로 순위를 반환. 중복 순위도 계산한다. |
| DENSE_RANK | 그룹 내 순위를 계산해서 NUMBER 타입으로 순위를 반환. 중복 순위는 계산하지 않는다. |
| COUNT | 행의 개수(차수)를 반환 |
| MIN | 행들의 최소값을 반환 |
| MAX | 행들의 최대값을 반환 |
| SUM | 행들의 합계를 반환 |
| AVG | 행들의 평균을 반환 |
| STDDEV | 행들의 표준 편차를 반환 |
| VARIANCE | 행들의 분산을 반환 |
1. RANK, DENSE_RANK
- RANK() OVER(ORDER BY 컬럼명 정렬순서) 형식으로 작성하며, 반드시 OVER 내부에 ODER BY 표현이 있어야 한다.
-- RANK
SELECT RANK() OVER(ORDER BY 컬럼명 정렬순서) FROM DUAL;
-- DENSE_RANK
SELECT DENSE_RANK() OVER(ORDER BY 컬럼명 정렬순서) FROM DUAL;
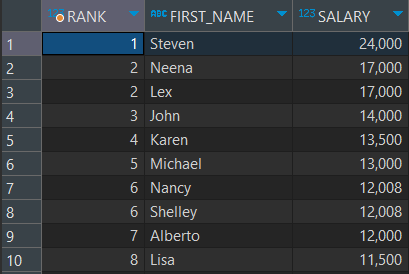
-- EMPLOYEES 테이블 사용
-- 급여 순위, 이름, 급여를 출력
SELECT RANK() OVER(ORDER BY SALARY DESC) AS "RANK", FIRST_NAME, SALARY
FROM EMPLOYEES;
![]()
-- EMPLOYEES 테이블 사용
-- 급여 순위, 이름, 급여를 출력
SELECT DENSE_RANK() OVER(ORDER BY SALARY DESC) AS "RANK", FIRST_NAME, SALARY
FROM EMPLOYEES;
- 위 사진과 비교했을 때 중복 순위가 들어가도 다음 순위 숫자가 순서대로 들어간다.
2. COUNT
- COUNT 사용 시 중복되는 컬럼 속성을 제외하고 행의 수를 얻고 싶다면 DISTINCT를 사용한다.
- COUNT(*)는 NULL을 포함한 모든 행을 체크하며, COUNT(컬럼명)은 NULL을 제외한다.
SELECT COUNT(*) FROM DUAL; -- 전체 행의 수 출력
SELECT COUNT(컬럼명) FROM DUAL; -- 특정 컬럼의 행의 수를 출력(NULL을 제외한다.)
SELECT COUNT(DISTINCT 컬럼명) FROM DUAL; -- 중복되는 컬럼 속성을 제외한 행의 수 출력
-- EMPLOYEES 테이블 사용
SELECT COUNT(*) FROM EMPLOYEES;
-- EMPLOYEES 테이블에서 보너스를 받는 사원 수를 출력
SELECT COUNT(COMMISSION_PCT) FROM EMPLOYEES;
-- 부서의 개수
SELECT COUNT(DISTINCT DEPARTMENT_ID) FROM EMPLOYEES;
107
35
11
3. MIN, MAX
-- MIN
SELECT MIN(컬럼명) FROM DUAL;
-- MAX
SELECT MAX(컬럼명) FROM DUAL;
-- EMPLOYEES 테이블에서 50번 부서에 속하는 사원들의 급여의 최대값과 최소값을 구하기
SELECT MIN(SALARY), MAX(SALARY)
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 50;
2100
8200
4. SUM
SELECT SUM(컬럼명) FROM DUAL;
-- EMPLOYEES 테이블에서 직종 번호에 IT를 포함하는 사원들의 급여 총 합 구하기
SELECT SUM(SALARY)
FROM EMPLOYEES
WHERE JOB_ID LIKE '%IT%';
28800
5. AVG
SELECT AVG(컬럼명) FROM DUAL;
-- EMPLOYEES 테이블에서 직종 번호에 IT를 포함하는 사원들의 급여 평균 구하기
SELECT AVG(SALARY)
FROM EMPLOYEES
WHERE JOB_ID LIKE '%IT%';
5760
6. STDDEV, VARIANCE
-- STDDEV
SELECT STDDEV(컬럼명) FROM DUAL; -- VARIANCE의 양의 제곱근
-- VARIANCE
SELECT VARIANCE(컬럼명) FROM DUAL;
-- EMPLOYEES 테이블에서 사원들 급여의 평균, 표준편차, 분산 구하기
SELECT AVG(SALARY),STDDEV(SALARY), VARIANCE(SALARY)
FROM EMPLOYEES;
6461.831775700934579439252336448598130841 // 평균
3909.579730552481921059198878167256201202 // 표준편차
15284813.66954681713983424440134015164874 // 분산